Нова модель DeepSeek знижує витрати на обробку довгих текстів майже вдвічі
Час читання: < 1 хв.
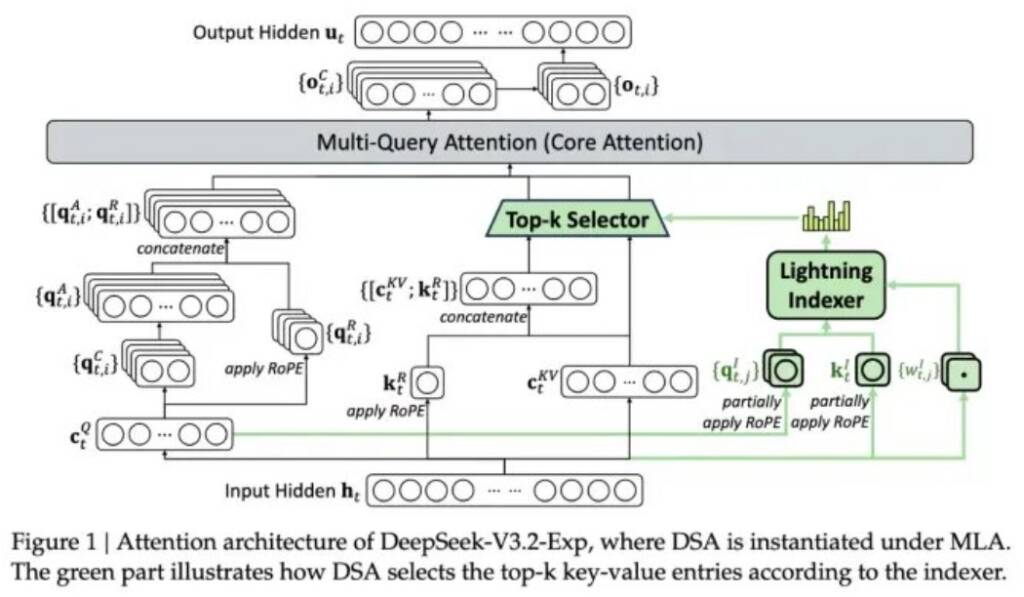
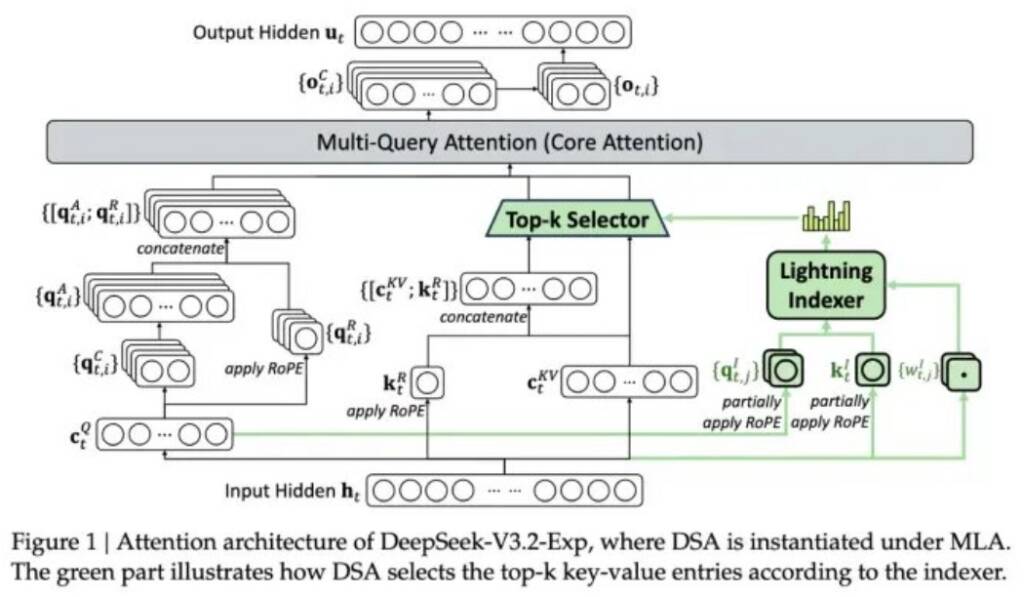
Компанія DeepSeek представила експериментальну модель V3.2-exp, призначену для значного зниження витрат при роботі з довгим контекстом. Анонс відбувся на Hugging Face разом із науковою публікацією на GitHub. Ключовою інновацією стала система DeepSeek Sparse Attention, що поєднує модулі lightning indexer для виділення важливих фрагментів і fine-grained token selection system для вибору окремих токенів усередині цих фрагментів. Це дозволяє обробляти довгі послідовності без суттєвого навантаження на сервер.
Перші тести показали, що у довгоконтекстних завданнях вартість API-запиту може знижуватись майже вдвічі. Хоча для повної оцінки потрібні додаткові випробування, відкриті ваги та вільний доступ на Hugging Face прискорюють незалежну перевірку ефективності.
Розробка V3.2-exp стала частиною стратегії DeepSeek щодо зменшення експлуатаційних витрат на «розумні» моделі, зосереджуючись на оптимізації архітектури, а не навчання нейромереж. Попередня модель R1 показала, що компанія здатна конкурувати з американськими розробниками за витратами, хоч і не викликала великого резонансу на ринку.
Нова технологія навряд чи створить такий самий ефект, як R1, проте вона може стати важливим уроком для глобальної індустрії, допомагаючи провайдерам ШІ-сервісів зменшувати витрати на роботу моделей без шкоди для продуктивності.
Запис Нова модель DeepSeek знижує витрати на обробку довгих текстів майже вдвічі спершу з’явиться на iTechua – Новини про смартфони, гаджети і різні девайси.